
I started my path to Linux Sysadmin with hardware. I began by fixing audio equipment and then came up through IBM as a Customer Engineer (CE) fixing everything from keypunches to mid-range computers like the IBM System/3 and then got into the IBM PC which ultimately led me into programming and system administration.
As a Sysadmin who also enjoys working with hardware, I have found that my knowledge of hardware has helped me solve problems many times. It also helps me understand the Linux operating system and many of the tools we use on a daily basis to locate and resolve problems with both hardware and software.
In this article I will cover aspects of hardware such as how the CPU works, the types of memory found in computer hardware and how they work together, and just a touch of history and why the architecture of today’s computers is what it is.
Let’s start with a bit of history.
First computers
The first computers were people. Humans have been performing calculations for millennia but 1613 is the first known use of the term computers as applied to people. They used their brains to compute even though they also used mechanical devices such as the abacus1, slide rule, the Friden calculator, and many other mechanical calculators to aid them.
In the 19th century Charles Babbage designed a massive mechanical calculator that he called the difference engine but it was beyond the technology of his time to construct. Some of the ideas Babbage had for his machine are the precursors of some of the elements in modern computers. For example, he visualized a “store” for data storage and the “mill” is a form of mechanical processor (CPU).
One of the first devices to foreshadow more modern computers was the Jacquard loom, circa 1860, which used punched cards to contain programs that automated the weaving process. Although other efforts to mechanize the weaving process preceded Jacquard and used paper tapes, they did not fully automate the looms but merely improved upon certain aspects of setting up the patterns to be woven.
The “Rocket Girls” are a group of more modern human computers. Their knowledge of mathematical formulae and computing procedures enabled them to perform complex calculations such as those required to put humans in orbit and recover them.
What constitutes a modern computer?
All of the calculating devices up through the middle of the 20th Century were calculating machines. They were very complex mechanical calculating machines but not computers. They could perform complex calculations according to rigid algorithms but all of them lacked one or more of the important characteristics of modern computers.
I did many on-line searches to find some sort of common agreement as to what those characteristics are. I found many lists but most of them seem centered around speed, reliability, and security. Although those are essential things for computers to have, they are not defining characteristics and can be applied to many things besides computers. So after additional research and some thoughts of my own I have formulated the following set of characteristics that define what we today call a computer.
1. Stored program
The stored program is one of the primary defining characteristics of the Universal Turing Machine as envisioned by Alan Turing and is a key attribute of all modern computers. Most of the mechanical calculators used external devices to store their programs. For example, the IBM 402 Accounting Machine and is successor, the IBM 403, represent one final expression of the external program devices as used in many businesses up through the 1970s. They used plugboards to program their machine calculating cycles and had just enough internal memory registers in the form of relays to store a few cumulative totals such as “department totals,” “weekly totals,” “monthly totals,” “yearly totals,” and so on. As a CE at IBM I used to work on these devices.
Stored program machines like modern computers use RAM memory to store their programs while they are being executed. The stored program concept opens up some powerful and interesting possibilities including the ability to modify the sequence of the program execution and the content and logic of the program.
2. Stored data
The IBM 402/403 accounting machines did not store the data on which they worked internally. The data was stored on 80-column punched cards that were fed into the accounting machine from a hopper, usually one card per computing cycle, under control of the plugboard program. Each card was one record. The cards required sorting and collating using specific criteria for each program prior to being fed into the hopper of the machine. This type of external data storage required the program to obtain its data in predetermined order by the sequence of the punched cards.
Modern computers store their data in RAM where it can be accessed at will during execution of the programs that operate on it. This means that the data can be accessed in any sequence and as many times as needed.
3. Unified memory space
This is an important convergence of stored program and stored data and provides a unified memory space in RAM for both programs and data in modern computers. The same storage space can be used for both programs and data. Because the program is stored in the same memory as data it is an easy matter for the program to access its own code as if it were just data. The result is that programs can operate upon themselves and modify their own code. Programs and data thus become interchangeable and can be manipulated using the same tools.
Using the single RAM data store for both programs and data simplifies the architecture of storage and access to it as well as making it more flexible for use in storing either programs or data in differing amounts for different applications.
4. Arithmetic operations
Computers perform arithmetic operations (maths) because that is what they are supposed to do. Modern computers perform many other types of operations on text as well as numerical data but to the CPU they all work the same way.
This characteristic seems to be left out of most of the lists I found because it would seem to be a basic assumption about what a computer is. I prefer to make this an explicit item in my list for the sake of completeness if nothing else.
5. Logical operations
In addition to the arithmetic operations performed by computers they must also perform various types of logical operations. These logical operations can be used determine two numeric values are equal or two character strings are the same. Among many other things, the results can be used to determine which program path to take for further processing or it can be used to determine when an algorithm has completed.
6. On-line storage
On-line storage refers to HDD, SSD or tape drives that stored the data and programs “on-line” for immediate access during program execution. Hot-pluggable storage devices notwithstanding, HDDs and SSDs are intended to store the operating system, programs, and data required by the host system and to remain on-line at all times. This makes both programs and data quickly available for transfer to RAM – without human intervention – where they can be accessed by the processor.
On-line storage is in contrast to so-called “off-line” storage. Off-line storage – which is not a required attribute for a computer – could be a removable disk or tape that would be mounted as required for specific programs. The data and programs stored in “off-line” storage required intervention by humans to be accessible by the computer. This is like inserting a CD, DVD, external USB or SATA storage drive, or USB thumb drive into your computer in order to access the data stored on it.
The legacy
The punched card was the primary storage medium for both data and programs for over a century. As a result the paradigm for data processing in the first digital computers was the same as that for the mechanical calculators they replaced, such as the IBM accounting machines. In this paradigm, each punched card represents one record. Even after computers were well-entrenched in modern business processes by the 1960’s, the punched cards containing data, such as customer information, employee data, accounting transactions, hours worked, and more, were used to perform many off-line tasks such as sorting the cards (records) into the proper sequence, extracting only cards that met specific criteria, merging cards from multiple sources into a single deck in a desired sequence, and much more. All this was to prepare a specific set of records for use as input to whatever program would use them as input on the computer itself.
In fact, this record-based approach is so pervasive in the mainframe world even today, that IBM’s MVS operating system still uses a record-based filesystem based on many of the same concepts as punched cards.
One early IBM language, Report Program Generator (RPG) was intentionally designed for IBM’s mid-range and small computers to mimic the calculation cycle of the IBM accounting machines. This was an effort explicitly intended to appeal to the many smaller companies still using the IBM accounting machines into the late 1970’s.
Any machine that used punched cards was generically referred to as a “unit record” type of device.
The Central Processing Unit (CPU)
The CPU in modern computers is the embodiment of Babbage’s “mill.” The term CPU originated way back in the mists of computer time when a single massive cabinet contained the circuitry required to interpret machine level program instructions to perform operations on the data supplied. All of the processing required by all of the attached peripheral devices such as printers, card readers, and early storage devices such as drum and disk drives, was also performed by the central processing unit. Modern peripheral devices have a significant amount of processing themselves and so can off-load some of that processing from the CPU thus freeing it up from input/output tasks so that its power can be applied to the primary task at hand.
Early computers had only a single CPU and so could only perform one task at a time.
We retain the term CPU today but it now typically refers to the processor package on a typical motherboard. A typical Intel processor package is shown in Figure 1.

There is really nothing to see here other than the processor package itself. The chip containing the processor(s) is sealed inside a metal container which is then mounted on a small printed circuit (PC) board. This assembly is the processor package and is simply dropped into place in the CPU socket on a motherboard and secured in place with a locking lever arrangement. A CPU cooler is mounted on the processor package. There are several different physical sockets with differing numbers of contacts so getting the correct package to fit the socket should be considered if you build your own computers.
How the CPU works
Let’s look at the CPU in more detail. Figure 2 provides us with a conceptual diagram of a hypothetical CPU so that you can more easily visualize the components being discussed. The RAM and system clock are shaded because they are not part of the CPU and are only shown for clarity. Also, in the interest of clarity, no connections between the CPU clock and the control unit to the rest of the components in the CPU are not shown. Suffice it to say that signals from the clock and the control unit are an integral part of every other component.
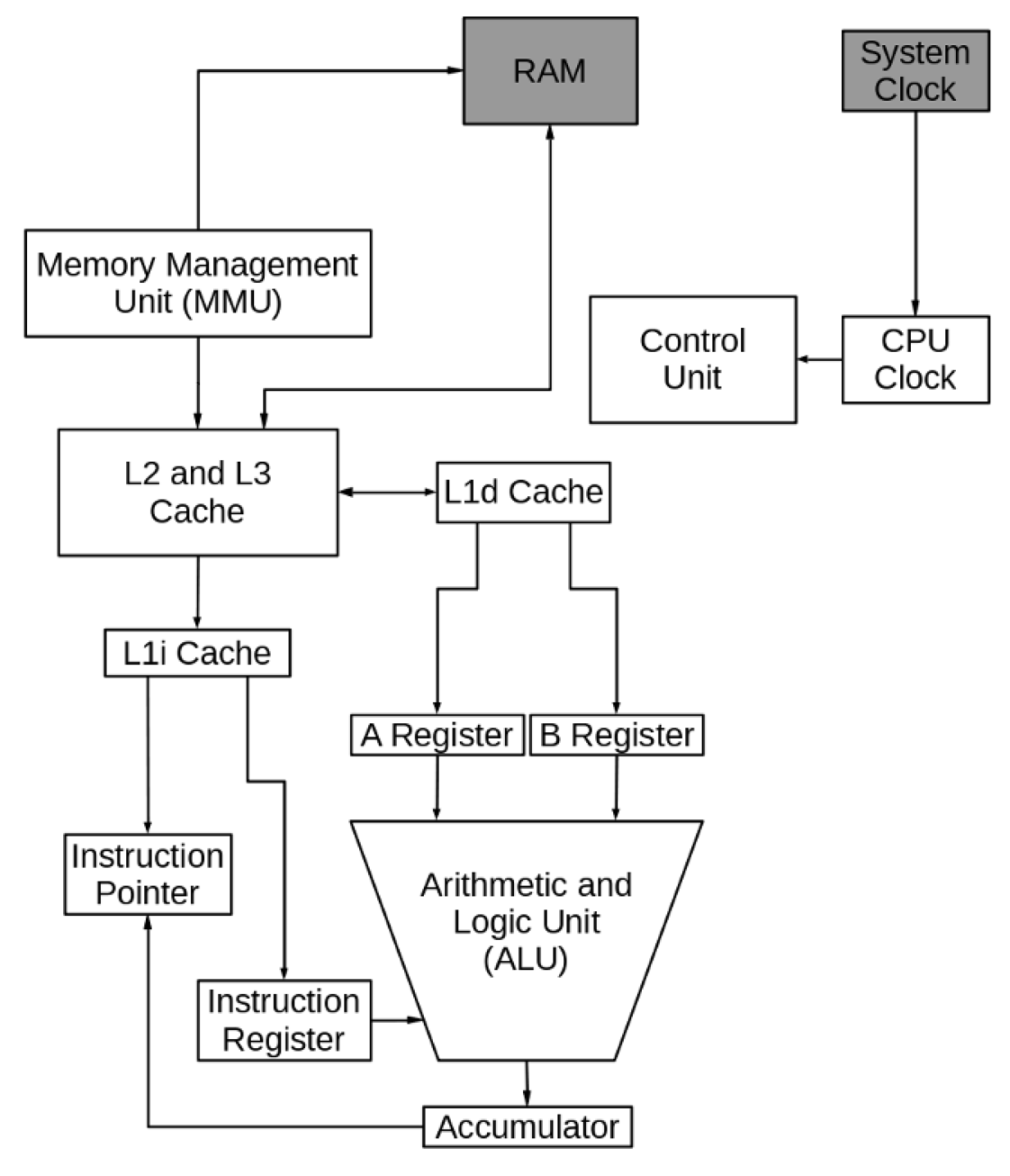
This does not look all that simple but the reality is more complex than it appears here. This figure will be sufficient for our purposes while not being overly complex.
Arithmetic and Logic Unit
The Arithmetic and Logic Unit is usually referred to as the ALU. As it’s name implies it performs the arithmetic and logical functions that are the work of the computer. The A and B registers hold the input data and the accumulator receives the result of the operation. The instruction register contains the instruction that the ALU is to perform.
As an example, for adding two numbers, one number is placed in the A register and the other in the B register. The ALU performs the addition and places the result in the accumulator. If the operation is a logical one, the data to be compared is placed into the input registers and the result of the comparison, a 1 or 0, is placed in the accumulator. Whether this is a logical or arithmetic operation, the accumulator content is then placed into the cache location reserved by the program for the result.
There is another type of operation that is performed by the ALU. The result is an address in memory and it can be used to calculate a new location in memory to begin loading instructions. The result is placed into the instruction pointer register.
Instruction Register and pointer
The instruction pointer points to the location in memory that contains the next instruction that will be executed by the CPU. When the CPU completes execution of the current instruction, the next instruction is loaded into the instruction register from the memory location pointed to by the instruction pointer.
After the instruction is loaded into the instruction register the instruction pointer register is incremented by one instruction address. This allows it to be ready to move the next instruction into the instruction register.
Cache
The CPU never accesses RAM directly. Modern CPUs have one or more layers of cache. The CPU is much faster in its ability to perform calculations than is RAM in its ability to feed enough data to the CPU. The reasons for this are beyond the scope of this article but we will explore that a little more in the next article.
Cache memory is faster than the system RAM and it is electrically closer to the CPU because it is on the processor chip. The function of cache is to provide faster memory for the storage of data and instructions to prevent the CPU from having to wait for the data to be retrieved from RAM. When the CPU needs data – and program instructions are also considered to be data – the cache determines whether the data is already in residence and provides it to the CPU.
If the requested data is not in the cache, the cache retrieves it from RAM and also uses some predictive algorithms to move more data from RAM into the cache. The cache controller analyzes the data requested and tries to predict what additional data will be needed from RAM and loads it into the cache. By keeping some data closer to the CPU in a cache that is faster than RAM, the CPU can remain busy and not waste CPU cycles waiting for data from RAM.
Our simple CPU has three levels of cache. Levels 3 and 3 are designed to predict what data and program instructions will be needed next, move that data from RAM and move it ever closer to the CPU so that it will be ready when needed. These cache sizes typically range from 1MB to 32MB in size depending upon the speed and intended use for the processor.
The Level 1 cache is closest to the CPU and, in our CPU, there are two types of L1 cache. L1i is the instruction cache and L1d is the data cache. Level 1 cache typically range from 64KB to 512KB.
Memory Management Unit
The memory management unit (MMU) manages the flow of data between main memory (RAM) and the CPU. It also provides memory protection required in a multitasking environment and conversion between virtual memory addresses and physical addresses.
CPU Clock and Control Unit
All of the components of the CPU must be synchronized in order to work together smoothly. The control unit performs this function at a rate determined by the clock speed and is responsible for directing the operations of the other units using timing signals that extend throughout the CPU.
RAM
Although the RAM, a.k.a, random access memory, or main storage, is shown in this diagram and the next, it is not truly a part of the CPU. Its function is to store programs and data so that they are ready for use when the CPU needs them.
How it works
CPUs work on a cycle that is managed by the control unit and synchronized by the CPU clock. This cycle is called the CPU instruction cycle and it consists of a series of fetch/decode/execute components. The instruction, which may contain static data or pointers to variable data, is fetched and placed into the instruction register. The instruction is decoded and any data is placed into the A and B registers. The instruction is executed using the data in the A and B registers with the result placed into the accumulator. The CPU then increases the value of the instruction pointer by the length of the previous one and begins again.
The basic CPU instruction cycle looks like this.

The need for speed
Although the basic CPU works perfectly fine, CPUs that run on this simple cycle can be improved upon to be utilized even more productively. There are multiple strategies for boosting CPU performance and we look at two of them here.
Supercharging the instruction cycle
One problem early CPU designers encountered was that of wasted time in the various CPU components. One of the early strategies for improving CPU performance is that of overlapping the portions of the CPU instruction cycle to more fully utilize the various components of the CPU.
For example, as soon as the current instruction has been decoded the next one can be fetched and placed into the instruction register. And as soon as that has occurred, the instruction pointer can be updated with the address in memory of the next instruction. Use of overlapping instruction cycles is illustrated in Figure 4.

This all looks nice and smooth but factors such as waiting for I/O can cause disruptions to this flow. Not having the proper data or instructions in cache requires that the MMU locate the correct ones and move them to the CPU and that can take some time. Certain instructions can take more CPU cycles to complete than others so that can also interfere with smooth overlapping.
Nevertheless this is a very powerful strategy for improving CPU performance.
Hyperthreading
Another strategy for improving CPU performance is known as hyperthreading. Hyperthreading makes a single processor core work like two CPUs with two data and instruction streams.
Adding a second instruction pointer and instruction register to our hypothetical CPU, as shown in Figure 5, causes it to work like two CPUs, executing two separate instruction streams during each instruction cycle. Also, when one execution stream is stalled while waiting for data – again, instructions are also data – the second execution stream can continue processing. Each core that implements hyperthreading is the equivalent of two CPUs in its ability to process instructions.
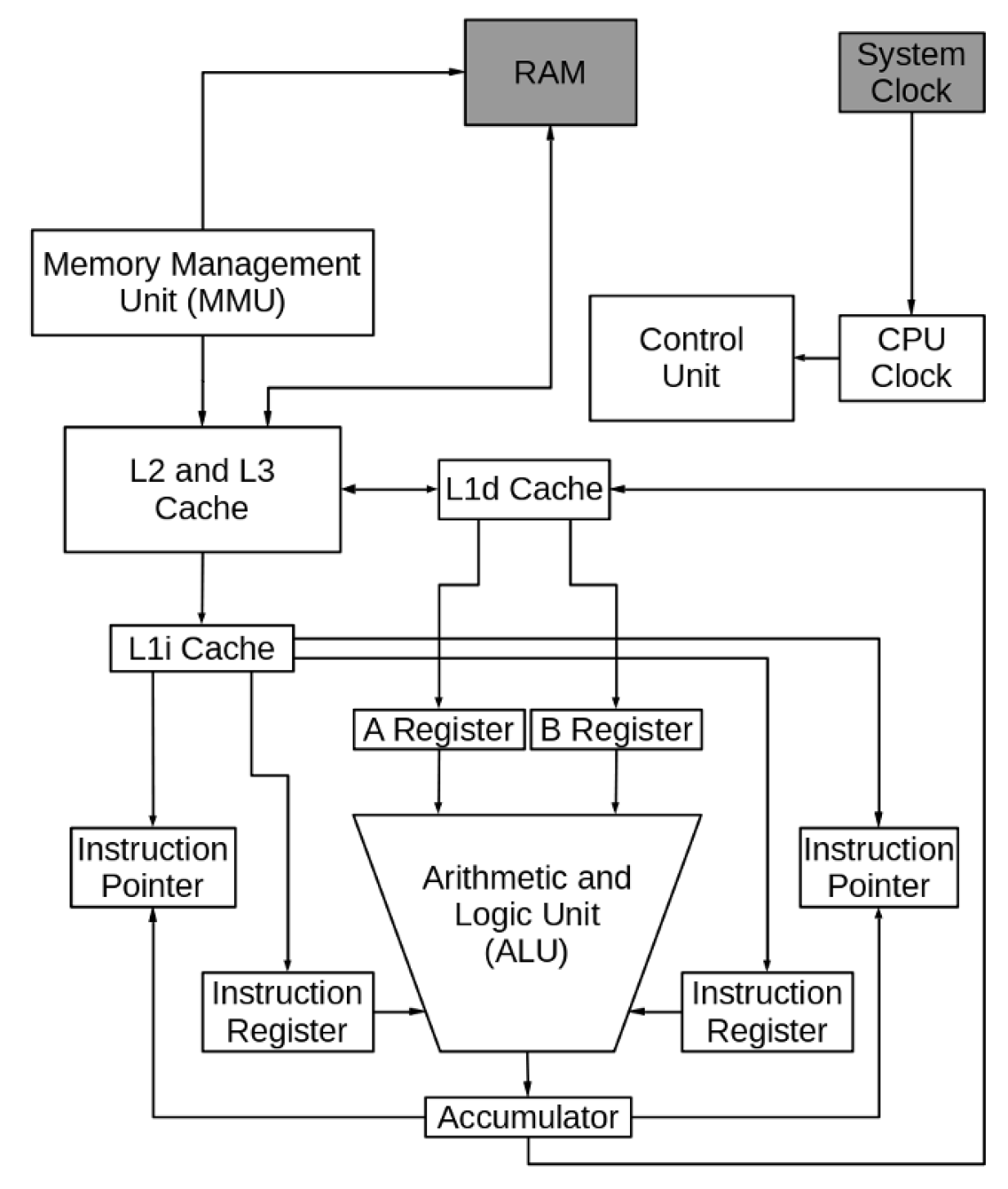
Remember that this is a very simplified diagram and explanation of our hypothetical CPU. The reality is far more complex.
More terminology
I have encountered a lot of differences in the use of terminology that refers to CPUs. To clear this up and define the terminology a little more explicitly, let’s look at the CPU itself using the lscpu command.
[root@hornet ~]# lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian Address sizes: 39 bits physical, 48 bits virtual CPU(s): 12 On-line CPU(s) list: 0-11 Thread(s) per core: 2 Core(s) per socket: 6 Socket(s): 1 NUMA node(s): 1 Vendor ID: GenuineIntel CPU family: 6 Model: 158 Model name: Intel(R) Core(TM) i7-8700 CPU @ 3.20GHz Stepping: 10 CPU MHz: 4300.003 CPU max MHz: 4600.0000 CPU min MHz: 800.0000 BogoMIPS: 6399.96 Virtualization: VT-x L1d cache: 192 KiB L1i cache: 192 KiB L2 cache: 1.5 MiB L3 cache: 12 MiB NUMA node0 CPU(s): 0-11
The Intel processor shown above is a package that plugs into a single socket on the motherboard. The processor package contains 6 cores. Each core is capable of hyperthreading so can run 2 simultaneous threads for a total of 12 CPUs. My definitions:
Core: A core is the smallest physical hardware unit capable of performing the task of processing. It contains one ALU and one or two sets of supporting registers. The second set of registers and supporting circuitry enables hyperthreading. One or more cores can be combined into a single physical package.
CPU: A logical hardware unit capable of processing a single thread of execution. The modern use of the term Central Processing Unit refers to the total number of threads that a processor package is capable of executing simultaneously. A single-core processor that does not support hyperthreading is the equivalent of a single CPU and in this case CPU and core are synonymous. A hyperthreading processor with a single core is the functional equivalent of two CPUs and a hyperthreading processor with 8 cores is the functional equivalent of 16 CPUs.
Package: The physical package such as that shown in Figure 1 that contains one or more cores.
Processor: 1. A device that processes program instructions to manipulate data. 2. Frequently used as a synonym for package.
Socket: Sometimes used as another synonym for package but it more accurately refers to the physical socket on the motherboard into which the processor package is inserted.
The terms socket, processor, and package are often used interchangeably which can cause some confusion. As we can see from the lscpu command results above, Intel has provided us with its own terminology and I consider that the authoritative source. In reality we all use those terms in various ways but so long as we understand each other at any given point that is what really matters.
Notice in the data about the processor above that it has 2 level-2 caches of 512KiB each; one for instructions, L1i, and one for data, L1d. Level 1 cache is that closes to the CPU and it speeds things up to have instructions and data separate at this point. Level 2 and Level 3 cache are larger but instructions and data co-exist in each.
What does this all mean?
Good question. Back in the early days of mainframes each computer had only a single CPU and was incapable of running more than one program at a time. They might run payroll, then inventory accounting, then customer billing, and more but only one program could run at a time. Each program had to finish before the system operator could start the next.
Some early attempts at running multiple programs at once took a simple approach and were aimed at better utilization of a single CPU. For example, programs 1 and 2 were loaded and program 1 ran until it was blocked waiting for I/O to take place. At that point program 2 would run until it was blocked. This approach was called multi-processing and helped to ensure that expensive computer time was more fully utilized.
Early attempts at multitasking all involved switching the execution context of a single CPU very rapidly between the execution streams of multiple tasks. This was not true multitasking as we understand it because, in reality, only a single thread of execution could be processed at a time. It was more correctly called time-sharing.
Modern computers from smart watches and tablets to supercomputers all support true multitasking with multiple CPUs. Having multiple CPUs enables computers to run many tasks simultaneously. Each CPU can perform its own tasks at the same time as all the other CPUs can. That means that an 8-core processor with hyperthreading, i.e., 16 CPUs can run 16 tasks truly at the same time.
Memory and storage
The terms “memory” and “storage” tend to be used interchangeably in the technology industry and the definitions of both in the Free Dictionary of Computing (FOLDOC) support this. Both can apply to any type of device in which data can be stored and later retrieved.
Volatility vs cost and speed
Although storage devices have well known attributes such as capacity and speed that affect how a particular device is utilized in a computer, the most important distinguishing characteristic is that of volatility.
Volatile memory can only retain the data stored in it so long as power is applied to it. Random access memory – RAM – comes in various speeds and sizes. It is made up of transistorized memory cells and is always volatile. It only retains the data stored in it so long as power is applied.
Non-volatile memory can retain the stored data even when power is removed. Disk drives are made of disks coated with magnetic material. The data is written using magnetic fields and the resulting magnetic data are retained as microscopic magnetic bits in circular strips on the disk. Disks and other magnetic media are non-volatile and can retain data even when power is removed.
As we have seen in the previous articles of this series, the CPU itself can perform its task faster than most memory can keep up with it. This has resulted in using predictive analysis to move data through multiple layers of ever faster cache memory to ensure that the needed data is available to the CPU when it is needed.
This is well and good but faster memory has always been more expensive than slower memory. Volatile memory is also more expensive than non-volatile.
Early storage
One early non-volatile memory device was paper tape with holes punched in it and a teletype machine with a paper tape reader. This had the advantage of being relatively inexpensive but it was slow and fragile. The paper tapes could be damaged so there were programs to duplicate paper tapes and patching kits. Typically the program was stored on tape and the data could be entered from the console or on another tape. Output could be printed to the console or punched into another tape.
Volatile storage was crude and could be banks of electro-mechanical relays for CPU A and B registers but that was very expensive. Another early volatile storage medium more suited to main storage than CPU registers was the Cathode Ray Tube (CRT). Each CRT could store 256 bits of data at a cost of about US$1.00 per bit. Yes – per bit.
Sonic delay line memory was used for a while and one of the keypunch machine types I maintained while I worked for IBM used a torsion wire version of this type of memory. This type of memory was very limited in capacity and speed, and it provided only sequential access rather than random but worked well for its intended use.
Magnetic disk and tape drive storage developed rapidly in the 1950’s and IBM introduced RAMAC, the first commercial hard disk in 1956. This non-volatile storage unit used 50 magnetic disks on a single, rotating spindle to store about 3.75MB – yes Megabytes – of data. Renting at $750/month the cost of this storage was about $0.47 per Byte per month.
Magnetic disks are what I like to call semi-random access. Data is written in thousands of concentric circular tracks on the disk and each track contains many sectors of data. In order to access the data in a specific sector and track the read/write heads must first seek to the correct track and then wait until the disk rotates so that the desired data sector comes under the head. As fast as today’s hard disk drives may seem, they are still quite slow when compared to solid state RAM.
Magnetic core memory was widely used in the 1950’s and `60’s and offered random access. It’s drawbacks were that it was expensive and slow. The cost of magnetic core memory started at $1.00 per bit but fell to about $0.01 per bit when manufacturing of the core planes was moved to Asia.
When transistors were invented in the 1950’s, computer memory – and other components as well – moved to the new semiconductor memory devices, which is also called solid state. This type of memory is volatile and the data is lost when power is removed.
By 1970 RAM memory had been compressed onto integrated circuit (IC) chips. As the ICs began packing more memory into smaller spaces, it also became faster. Initial costs of IC memory was around $0.01 per bit or 8 cents per Byte.
The first solid state drive (SSD) was demonstrated in 1991. SSD technology uses Flash RAM to store data on a non-volatile semiconductor memory device. This technology continues in use today in SD memory cards and thumb drives. SSD devices are much faster than rotating disk hard drives but still significantly slower than the RAM used for main storage.
Today
Today’s hard drives can contain as much as several Terabytes of data on a magnetic, non-volatile recording medium. A typical 4TB hard drive can be purchased for about $95 so the cost works out to about $0.0000000023 per Byte. Modern RAM can be had in very large amounts and it is very fast. RAM can cost as little as $89 for 16GB which works out to about $0.00000055625 per Byte. At that rate, 4TB of RAM would cost about $22,250 so RAM storage is still around 250 times more expensive than hard drive storage.
Although not the primary subject of this article, we also have so-called off-line storage such as CD/DVD-ROM/RW devices, and removable media such as external hard drives and tape drives.
Different storage types working together
We have disk drives that store up to multi-Terabytes of data in a non-volatile medium. They are slower than any type of semiconductor memory and do not provide true random access so are not suitable for use as main storage to which the CPU has direct access. We also have fast RAM which is significantly more expensive than disk drive storage but it is fast and the CPU can have direct access to it. Thumb drives, CD/DVD and other storage types can be used for storage of data and programs when they are needed infrequently or perhaps only at the time the program is installed.
So our computers use a combination of storage types. We have on-line storage with Gigabytes of RAM for storing programs and data while they are being worked on by the CPU. We have HDD or SSD devices that provide Terabytes of hard drive space for long-term storage of data so that it can be accessed at a moments notice. Figure 6 shows how this all works together.

The data closest to the CPU is stored in the cache which is the fastest RAM in the system. It is also the most expensive memory. Primary storage is also RAM but not as fast or as expensive as cache. When the CPU needs data – whether the program code or the data used my the program – it is provided by the cache when possible. If the data is not already in the cache, the CPU memory management unit locates it in RAM and moves it into cache from which it can be fed to the CPU as instructions or data.
Program code and the data used by those programs is stored on on-line storage such as a hard disk drive (HDD) or solid state drive (SDD) until it is needed. Then they are loaded into RAM so they can be accessed by the CPU.
Archival storage is primarily used for long-term purposes such as backups and other data archives. The storage medium is typically high-capacity tapes which are relatively inexpensive but are also the slowest in terms of accessing the data stored on them. However USB thumb drives and external drives can also be used for archival storage. Backups and archive data tend to be stored off-site in secure, geographically separate facilities which makes them time-consuming to retrieve when needed.
The data from archival and off-line storage can be copied to the on-line storage device or directly into main storage. One excellent example of the latter is the Fedora live USB thumb drives. The system can be booted directly to these thumb drives because they are mounted and used just as the on-line hard drive storage for this use case.
Convergence
The storage picture I have described so far has been fluid since the beginning of the computer age. New devices are being developed all the time and many that can be found in the historical time-lines of the Computer History Museum have dropped by the wayside. Have you ever heard of bubble memory?
As storage devices evolve, the ways in which storage is used can also change. We are seeing the beginnings of a new approach to storage that is being led by phones, watches, tablets, single board computers (SBCs) such as Arduino and Raspberry Pi. None of these devices uses hard drives for storage. They use at least two forms of RAM – one such as an micro-SD card for on-line storage and faster RAM for main memory.
I fully expect that the cost and speed of these two types of RAM to converge so that all RAM storage is the same: fast, inexpensive, and non-volatile. Solid state storage devices with these characteristics will ultimately replace the current implementation of separate main and secondary storage.
- The abacus is generally considered to be the first mechanical device used by humans to aid in performing mathematical calculations. The Abacus was developed in what is now Iraq around 4,300 to 4,700 years ago. https://en.wikipedia.org/wiki/Abacus ↩︎